
2次元のリスト
import pprint #自動で整形してプリントしてくれるpprintモジュール
#pprint.pprint(L2)#二回繰り返すのはなぜ?意味わからん(2019/12/4)
#(意味分かった
from pprint import pprint#とすれば一回で大丈夫)
pprint(L2)
#出力
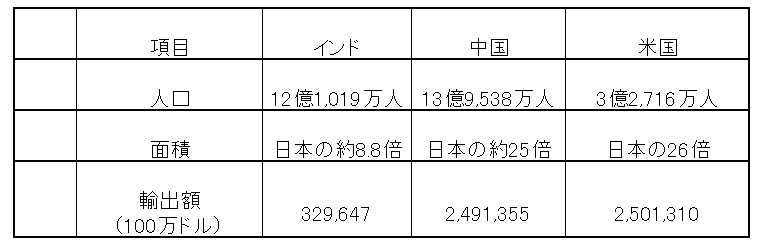
L2=[[‘項目’, ‘インド’, ‘中国’, ‘米国’],
[‘人口’, ’12億1,019万’, ’13億9,538万人’, ‘3億2,716万人’],
[‘面積’, ‘日本の約8.8’, ‘日本の約25倍’, ‘日本の26倍’],
[‘輸出額(100万ドル)’, 329647, 2491335, 2501310]]
#出力
print(‘L2[0]=’,L2[0])
print(‘L2[1]=’,L2[1])
print(‘L2[2]=’,L2[2])
print(‘L2[3]=’,L2[3])
————————————————–
L2[0]= [‘項目’, ‘インド’, ‘中国’, ‘米国’]
L2[1]= [‘人口’, ’12億1,019万’, ’13億9,538万人’, ‘3億2,716万人’]
L2[2]= [‘面積’, ‘日本の約8.8’, ‘日本の約25倍’, ‘日本の26倍’]
L2[3]= [‘輸出額(100万ドル)’, 329647, 2491335, 2501310]
print(‘L2[0][0]{} ,L2[0][1]{} ,L2[0][2]{} ,L2[0][3]{}’.format(L2[0][0],L2[0][1],L2[0][2],L2[0][3]))
print(‘L2[1][0]{} ,L2[1][1]{} ,L2[1][2]{} ,L2[1][3]{}’.format(L2[1][0],L2[1][1],L2[1][2],L2[1][3]))
print(‘L2[2][0]{} ,L2[2][1]{} ,L2[2][2]{} ,L2[2][3]{}’.format(L2[2][0],L2[2][1],L2[2][2],L2[2][3]))
print(‘L2[3][0]{} ,L2[3][1]{} ,L2[3][2]{} ,L2[3][3]{}’.format(L2[3][0],L2[3][1],L2[3][2],L2[3][3]))
————————————————–
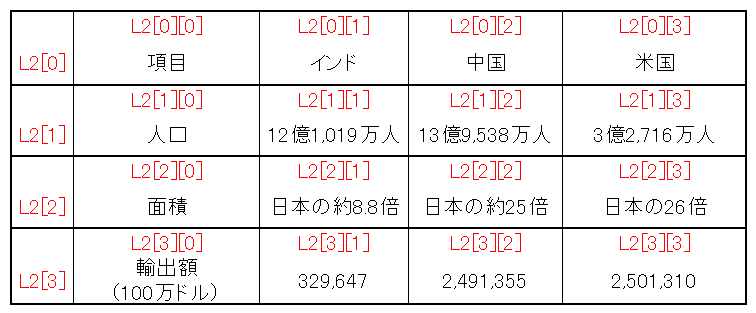
L2[0][0]項目 ,L2[0][1]インド ,L2[0][2]中国 ,L2[0][3]米国
L2[1][0]人口 ,L2[1][1]12億1,019万 ,L2[1][2]13億9,538万人 ,L2[1][3]3億2,716万人
L2[2][0]面積 ,L2[2][1]日本の約8.8 ,L2[2][2]日本の約25倍 ,L2[2][3]日本の26倍
L2[3][0]輸出額(100万ドル) ,L2[3][1]329647 ,L2[3][2]2491335 ,L2[3][3]2501310
#ポインタがあった?何でしょう????
print(‘{[0]}’.format(*L2))
print(‘{[0]}’.format(*L2[0]))
print(‘{[1]}’.format(*L2[0]))
print(‘{[1]}’.format(*L2))
print(‘{[2]}’.format(*L2))
————————————————–
項目
項
目
インド
中国
Python の * 演算子 (iterable unpacking operator) の使い方
リストをpandasに
from pprint import pprint
import pandas as pd
L2=[]
L2=[
[’12億1,019万’,’日本の約8.8′,329647],
[’13億9,538万人’,’日本の約25倍’,491335],
[‘3億2,716万人’,’日本の26倍’,22501310]]
df=pd.DataFrame(L2)
#print(df)
print(‘dataframeの行数・列数の確認==v\n’,df.shape)
(3, 3)
print(‘dataframeの各列のデータ型を確認==v\n’,df.dtypes)
0 object
1 object
2 int64
dtype: object
print(df.head())
0 1 2
0 12億1,019万 日本の約8.8 329647
1 13億9,538万人 日本の約25倍 491335
2 3億2,716万人 日本の26倍 22501310
#コラム名とインデックスを付ける
df.index =[‘India’,’China’,’USA’]
df.columns =[‘人口’,’面積’,’輸出額(100万ドル)’]
print(‘indexの確認==v\n’,df.index)
Index([‘India’, ‘China’, ‘USA’], dtype=’object’)
print(‘columnの確認==v\n’,df.columns)
column([‘人口’, ‘面積’, ‘輸出額(100万ドル)’], dtype=’object’)
print(‘df[[\’人口\’]]\n’,df[[‘人口’]])
India 12億1,019万
China 13億9,538万人
USA 3億2,716万人
print(‘df[[\’人口\’,\’面積\’]]\n’,df[[‘人口’,’面積’]])
人口 面積
India 12億1,019万 日本の約8.8
China 13億9,538万人 日本の約25倍
USA 3億2,716万人 日本の26倍
print(‘0行目から1行目まで\n’,df[0:2])
人口 面積 輸出額(100万ドル)
India 12億1,019万 日本の約8.8 329647
China 13億9,538万人 日本の約25倍 491335
print(‘df.loc[\’USA\’]\n’,df.loc[‘USA’])
人口 3億2,716万人
面積 日本の26倍
輸出額(100万ドル) 22501310
Name: USA, dtype: object
print(‘df[df[\’輸出額(100万ドル)\’] > 1000000]\n’,df[df[‘輸出額(100万ドル)’] > 1000000])
人口 面積 輸出額(100万ドル)
USA 3億2,716万人 日本の26倍 22501310
#—————————
データ取得元

コメント