
summary ob pandas.DataFrame
↓コード例集なのでこのままは動きません
import numpy as np
import pandas as pd
import dfgui
#https://pythondatascience.plavox.info/
#Numpy の 行列からデータフレームを作成する
matrix = np.random.randn(6,4)
df = pd.DataFrame(matrix, columns=list('ABCD'))
#ディクショナリからデータフレームを作成する
my_df = pd.DataFrame.from_dict(my_dict)
#先頭,末尾 N 行を表示する
df.head(N)
df.tail(N)
#基本統計量を算出する
#件数 (count)、平均値 (mean)、標準偏差 (std)、最小値(min)、第一四分位数 (25%)、中央値 (50%)、第三四分位数 (75%)、最大値 (max
df.describe()
#各列の型を確認する
df.dtypes
#列名を表示する
df.columns
#行名 (index) を表示する
df.index
#列名、行名を除いた値のみの2 次元行列として表示する
df.values
#特定の列を取得する(2種類とも同じ)
df['A']
df.A
#指定した区間の行を抽出する
df[1:3]#1~3row
df['20200102':'20200104']#indexで指定
#loc アトリビュートを使って特定の行・列を抽出する
df.loc["2013-01-01"]
## 行名 = "20130102" ~ "20130104" の "A" 列と "B" 列を取得
df.loc['20130102':'20130104',['A','B']]
## 行名 = "20130102" の "A" 列と "B" 列を取得
df.loc['20130102',['A','B']]
#行や列の位置を指定して行・列を取得する
## 3 行目を取得
df.iloc[3]
## 1,2,4 行目と 0-2 列目を取得
df.iloc[[1,2,4],[0,2]]
## 1-3 行目と全ての列を取得
df.iloc[1:3,:]
## 全ての行と 1-3 列目を取得
df.iloc[:,1:3]
#条件を指定して行・列を取得する(条件式)
## "A" 列の値が 0 より大きい行を取得
df[df.A > 0]
## 値が 0 より大きい値のみを取得
df[df > 0]
# "E" 列に "one" または "two" を値に持つ行(isin())
df[df['E'].isin(['one','two'])]
#データフレーム df と df2 を結合
df.append(df2,ignore_index=True)#新たな行番号を割り当てる
#列 (カラム) を追加する
## 列 "job" を追加
df['job'] = ["Engineer", "Sales"]
## 列 "age" を追加 (Numpy Array を追加)
df['age'] = np.array([35, 25])
#特定の行・列を削除する(drop())
##特定の行を削除する
df.drop([3,4])
##特定の列を削除する(axis=1 を指定し、列の削除であることを指定)
df.drop("A", axis=1)
#Python の del ステートメント
##列 A を削除
del df['A']
#行の長さを確認する
len(df.index)
#列の長さを確認する
len(df.columns)
#行と列の長さを確認する
df.shape
#行⇔列を転置する (T=Transpose)
df.T
#インデックス (行名・列名) に基づいてソートする
## 行名に基づいてソート
df.sort_index(ascending=False)
## カラム名 (列名) に基づいてソート
df.sort_index(axis=1, ascending=False)
#値に基づいてソートする
## B 列の値の小さい順 (昇順) にソート
df.sort_values(by='B')
# C 列の値の大きい順 (降順) にソート
df.sort_values(by='C', ascending=False)
#Pandas でデータフレームの結合 (マージ, JOIN)
df.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
#2 つのデータフレームを縦方向に結合する (concat)
pd.concat([df1, df2], ignore_index=True)
#Pandas で CSV ファイルやテキストファイルを読み込む
df=pd.read_csv(filepath_or_buffer, header='infer',encoding='utf-8')
#Pandas のデータフレームを CSV ファイルやテキストファイルに出力する
df.to_csv(path_or_buf=None, columns=None, header=True, index=True,
index_label=None, mode='w', encoding=None,line_terminator='\n')
pandasのデバッッグの友dfgui.show()
pandasがわかりにくいのはデータが見えないからだ
あーエクセルは良いわ~ って思うよね。
そこで
import dfgui
dfgui.show(df) #df=DataFrameオブジェクト
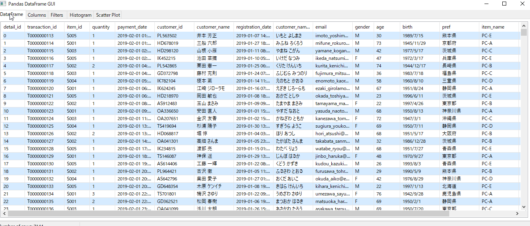
エクセルのビューワーという感じです
データを読み込んだり加工したりする度、これでデータをチェックします。
dfgui.show(dfオブジェクト名)
これだけですから。
dfguiモジュールはインストールが面倒、というか駄目だ
dfguiがインストールされていないとエラーになりますが、pipでは入らない
Traceback (most recent call last):
File "<module1>", line 12, in <module>
ModuleNotFoundError: No module named 'dfgui'まずwindowsのgit.exeをインストール

Git - Downloading Package
git-scm.com
インストールされたgitbash上でコレを実行↓
pip install git+https://github.com/bluenote10/PandasDataFrameGUI
作業ディレクトリにコピーされたので、次にpipをするためにanacondaプロンプト上で
https://github.com/bluenote10/PandasDataFrameGUIに有った呪文をコピペして実行
git clone "https://github.com/bluenote10/PandasDataFrameGUI.git"
cd dfgui
pip install -e .
conda package --pkg-name=dfgui --pkg-version=0.1 # this should create a package file
conda install --offline dfgui-0.1-py27_0.tar.bz2 # this should install into your conda environment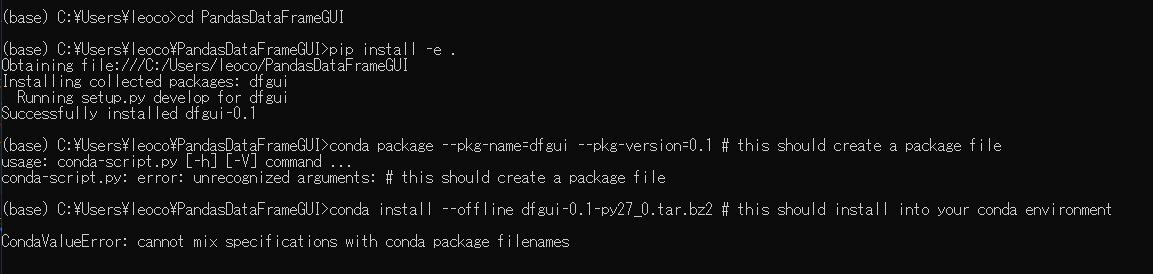
よくわからん
試しにプログラムを実行してみると
![]()
wxモジュールがないと言ってる
pip install wxしても、wxなんて知りませんなと来た。
pip install wxpython
これがモジュール名らしい。
やっと整ったよいなので、以前動いていたソースを実行してみる。
#https://note.nkmk.me/python-pandas-datareader-stock-population/
#pandas_datareaderのインストール
#pip install git+https://github.com/pydata/pandas-datareader.git
#pip install wxpython
#
#yahoofinanceから、表示したい一社のシンボルをINPUTしてグラフ化
#importは何が必要なのかよくわからない
import pandas_datareader.data as web #要pip
import datetime
import matplotlib.pyplot as plt
import webbrowser#標準モジュールpip不要
import dfgui
import os, tkinter, tkinter.filedialog, tkinter.messagebox
from pandas.util.testing import assert_frame_equal
import time
end = datetime.datetime.today()
start = end-datetime.timedelta(days=732)#日数
while True:
#stock1=''
stock1=input('input ticker (h=help) > ')#ticker input,日本で言う証券コード
if stock1=='end':#終了
break
elif stock1=='list':#SBI証券の外国株一覧ページを開く
webbrowser.open('https://search.sbisec.co.jp/v2/popwin/info/stock/pop6040_usequity_list.html')
#メイン処理,OHLCを読み込んで表示
elif stock1=='h' or stock1=='help':
print (''' [h] help
[list] open listing site(SBI証券アメリカ株一覧のページを勝手に開くぞよ)
[end] END ''')
else :
try:
f1 = web.DataReader(stock1, 'yahoo', start, end)
#エクセル的なGUIの表示
dfgui.show(f1)
#OHLCのclose価格をグラフ化
f1['Close'].plot(title='YAHOO finance '+stock1, grid=True)
plt.show()
except:
print('SYMBOL名が間違っていませんか?')
動かない・・・・

コメント