[python]
'''
三菱UFJのサイトから「店舗・ATM」をスクレイピングするコード
'''
from urllib import request # urllib.requestモジュールをインポート
from bs4 import BeautifulSoup # BeautifulSoupクラスをインポート
turl=[
['01',0,'北海道'],
['04',0,'宮城県'],
['08',0,'茨城県'],
['09',0,'栃木県'],
['10',0,'群馬県'],
['11',4,'埼玉県'],
['12',5,'千葉県'],
['13',36,'東京都'],
['14',9,'神奈川県'],
['15',0,'新潟県'],
['17',0,'石川県'],
['21',0,'岐阜県'],
['22',0,'静岡県'],
['23',24,'愛知県'],
['24',0,'三重県'],
['25',0,'滋賀県'],
['26',2,'京都府'],
['27',17,'大阪府'],
['28',5,'兵庫県'],
['29',0,'表示させているだけ、以下省略'],
['30',0,''],
['33',0,''],
['34',0,''],
['35',0,''],
['36',0,''],
['37',0,''],
['40',0,''],
['42',0,''],
['43',0,'']
]
def gettext():
response = request.urlopen(url)
soup = BeautifulSoup(response)
response.close()
# 得られたsoupオブジェクトを操作していく
print(soup.title.text)
for t in soup.find_all(class_="tenpo_detail"):
texts=t.get_text()
#print(texts.strip())
print(texts.replace('\n',''))
for i in range(27):#27都道府県にしかない
url = 'http://map.bk.mufg.jp/b/bk_mufg/attr/{}/'.format(turl[i][0])
#print(url)#URLを出力してみる
gettext()#テキストの出力
if turl[i][1]!=0:#次へページがある場合
for j in range(2,turl[i][1]+1):#20件以上で次へページがある場合
url='https://map.bk.mufg.jp/b/bk_mufg/attr/?start={}&kencode={}'.format(j,turl[i][0])
#print(url)
gettext()
'''
https://map.bk.mufg.jp/b/bk_mufg/attr/13/ #東京都は13
https://map.bk.mufg.jp/b/bk_mufg/attr/?start=2&kencode=13 #13-2
https://map.bk.mufg.jp/b/bk_mufg/attr/?start=36kencode=36 #13-36
'''
[/python]
1店舗の情報が、1行にくっついてしまったので、エクセルで分割する。
メニューバー[データ][区切り位置]
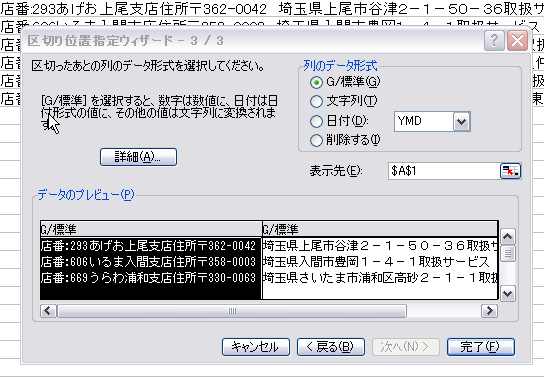
こんなことを何回か繰り返すと、整形したデータになる。
CSVにしてgooglemap
[三][マイプレイス][マイマップ][地図を作成]
新規のマイマップが作成されるので
[インポート]先に作ったデータをドロップ。
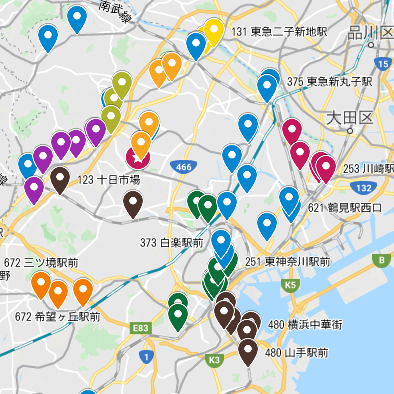
アイコンや色は自由に変えられる。
縮尺もいつもの様にグルグル動かせる。