このデータを料理します cvs2018.xlsx
| 今日のころちん | セブンイレブン | ファミリーマート | ローソン | ミニストップ | デイリ−マート | サークルK | セイコーマート |
| 1 | 東京都 | 2,634 | 2,356 | 1,723 | 292 | 146 | 169 |
| 2 | 大阪府 | 1,197 | 1,332 | 1,129 | 95 | 142 | 68 |
| 3 | 神奈川県 | 1,400 | 965 | 1,092 | 141 | 97 | 73 |
| 4 | 愛知県 | 1,054 | 1,379 | 683 | 219 | 78 | 292 |
| 5 | 北海道 | 989 | 233 | 655 | – | – | 3 |
| 6 | 埼玉県 | 1,196 | 784 | 675 | 158 | 78 | 11 |
| 7 | 千葉県 | 1,090 | 621 | 611 | 200 | 141 | 12 |
その前に sheet Range cell の指定の仕方
どのオブジェクトから、メソッドで指定されるか、プロパティで指定されるかによって構文が変わります。openpyxlは複雑に見えますが、複雑なのはエクセルです。
オブジェクト毎のメソッドはxlwingsのページにまとめました、エクセルの仕様なので、openpyxlもほぼ同じと思われます。プロパティでの呼び出し方はまとめて有りません。(._.)
オブジェクトの依存関係につて、いい感じの画があったので、「やさしいマクロとVBA」様から引用させていただきます。
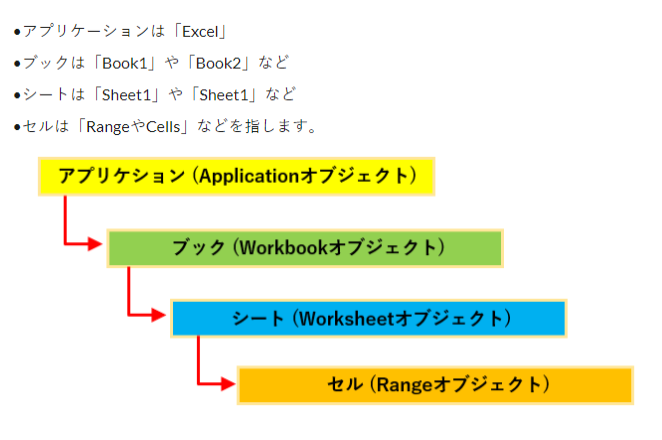
4層の各オブジェクトは複数集まって、〇〇sという階層が上あります。
オブジェクトと、集合体のコレクションと言う概念があるのですが、無視しましょう。
本来の階層は apps.app1.books.book1.sheets.sheet1.range(‘A1’) です

↑はVBAの構文ですが、openpyxlも(階層は)全くこのままですね。
pythonは大文字小文字が区別されるので要確認です。
workbookがエクセルの1つのファイルです。その中にシートが有りその中にセルがあり、セルの集まりがRangeです。
appricationはエクセルファイルを動かすエクセルプログラムです。エクセルファイルそのものがエクセルプログラムと思ってしまいがちですが、エクセルファイルはただのデータです。
どのオブジェクトからどう呼び出しているかを意識して、呼び出し方を統一しないとバグりそうです。
openpyexl
import openpyxl
bookオブジェクトにファイルを読み込む
wb = openpyxl.load_workbook('cvs2018.xlsx')
print(wb.sheetnames)#シート全部を取得
print(wb.get_sheet_names())#同上
# ['Sheet1', 'Sheet2', 'Sheet3']シートの操作
for文でシート名一覧を表示
for sheet in wb:
print(sheet.title)
#>Sheet1
#>Sheet2
#>Sheet3sheetを取得(3つの方法/どのオブジェクトかによって呼び出し方が変わる)
ws1 = ['Sheet1'] #1番目の方法
ws2 = book.worksheets[2] #2番めの方法
ws3 = book.get_sheet_by_name('Sheet3') #3番めの方法シートの作成・削除(オブジェクト名とシート名を混同しないこと)
ws4 = wb.create_sheet(title='Sheet4', index=4)#作成シート名'Sheet5',5番目のシート
ws5 = wb.copy_worksheet(ws1)#book内コピー
ws5.title = 'Sheet5'
print(wb.sheetnames)
wb.remove(ws4)#削除
print(wb.sheetnames)
セルの操作
セルの値を取得
print(ws1['B2'].value)
print(ws1.cell(row=2,column=2).value)
#>東京都cellオブジェクトからセルを操作
a1 = ws1.cell(1,1)
print('A1:',a1.value)
#まとめprint(ws1.cell(1,1).value)
#>入ってたもの
—— セルの操作 ————–
print(ws1['B2'].value)
print(ws1.cell(row=2, column = 2).value)
#>東京都cellオブジェクトからセルを操作
a1 = ws1.cell(1, 1)
print('A1:', a1.value)
#>入ってたものA1の値を上書き
a1.value = "何通りもいらんぜよ"
print(a1.value)値の書き込み
ws2 = wb['Sheet2'] #Sheet2を読み込む
#ws2.title = '4WRITE' #Sheet2の名前を"4WRITE"に変更
ws2['B1'] = 'TEST' #レンジA1に"TEST"と投入ws2 = wb['Sheet2'] #Sheet2を読み込む
#ws2.title = '4WRITE' #Sheet2の名前を"4WRITE"に変更
ws2['B1'] = 'TEST' #レンジA1に"TEST"と投入
セルに式を投入(=式の文字列)
ws2.cell(9,3,value=" = sum('c2:c7')")
print(ws2.cell(9,3).value)
# =sum('c2:c7')セルの列の記号を取得
print(a1.column_letter)
#>A
print(a1.coordinate)
#>A1列名、行番号、値を出力
print('列' + str(range1.column) + # 列名のみを取得
', 行' + str(range1.row) + # 行番号のみを取得
' : ' + range1.value) # セルの値を取得
#列2, 行2 : 東京都# セル番地、値を出力
print('セル' + range1.coordinate + # 行列のセル番地を取得
' : ' + range1.value) # セルの値を取得
#セルB2 : 東京都range[A1]のAを数字で指示
for i in range(65,69): # A-D
rng = chr(i)+'1' # A1-D1
print(ws2[rng].value) # ws2[A1].value - ws2[D1].valuefor文で行と更にforで列を取得
cv = []#cell.value
for row in ws1.rows:
for cell in row:
#print(cell.value)
cv.append(cell.value)
print(cv)['何通りもいらんぜよ', 'セブンイレブン', 'ファミリーマート', 'ローソン', 'ミニストップ', 'デイリ−マート',・・・・・・・・・・・for文で行を取得しつつ更にforで列を取得
tpl = ws1['A1:D5']
for i in tpl:
for j in i:
print(j.value)今日のころちん
セブンイレブン
ファミリーマート
ローソン
1
東京都
2634
2356
・・・・
4
愛知県
1054
1379for文で行を取得しつつ更にforで列を取得(1行目と1列目は読み込まない)
for row in ws1.iter_rows(min_row = 2, min_col = 2):#iter_rows(min_row = 2,min_col = 2) :
for cell in row:
print(cell.value)東京都
2634
2356
1723
292
146
169
None
None
・・・・
千葉県
1090
621
611
200
141
12
None
Noneコードまとめ
import openpyxl
#bookオブジェクトにファイルを読み込む
wb = openpyxl.load_workbook('cvs2018.xlsx')
print(wb.sheetnames)#シート全部を取得
print(wb.get_sheet_names())#同上
#>['Sheet1', 'Sheet2', 'Sheet3']
#for文でシート名一覧を表示
for sheet in wb:
print(sheet.title)
#>Sheet1
#>Sheet2
#>Sheet3
#------ sheetを取得(3つの方法) --------------
ws1 = wb['Sheet1'] #1番目の方法
ws2 = wb.worksheets[2] #2番めの方法
ws3 = wb.get_sheet_by_name('Sheet3') #3番めの方法,シート名で取得
#シートの作成・削除(オブジェクト名とシート名を混同しないこと)
ws4 = wb.create_sheet(title='Sheet4', index=4)#作成シート名'Sheet5',5番目のシート
ws5 = wb.copy_worksheet(ws1)#book内コピー
ws5.title = 'Sheet5'
print(wb.sheetnames)
wb.remove(ws4)#削除
print(wb.sheetnames)
#------ セルの操作 --------------
print(ws1['B2'].value)
print(ws1.cell(row = 2, column = 2).value)
#>東京都
#cellオブジェクトからセルを操作
a1 = ws1.cell(1,1)
print('A1:',a1.value)
#>入ってたもの
#A1の値を上書き
a1.value = "何通りもいらんぜよ"
print(a1.value)
# 値の書き込み
ws2 = wb['Sheet2']#Sheet2を読み込む
#ws2.title = '4WRITE'#Sheet2の名前を"4WRITE"に変更
ws2['B1'] = 'TEST'#レンジA1に"TEST"と投入
#セルC9 = cell(9,3)に式を投入
ws1.cell(9,3,value = "=sum(c2:c7)")
ws1.cell(9,4).value=' = sum(d2:d7'#D9にも
#セルの列の記号を取得
print(a1.column_letter)
#>A
print(a1.coordinate)
#>A1
openpyxl.utils.column_index_from_string("AX")
#>50
tpl = ws1['A1:D5']
print(tpl)
#((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>, <Cell 'Sheet1'.D1>),・・・
#for文で行と更にforで列を取得
cv = []#cell.value
for row in ws1.rows:
for cell in row:
#print(cell.value)
cv.append(cell.value)
print('print(cv)',cv)
#['今日のころちん', 'セブンイレブン',・・・・・
#for文で行を取得しつつ更にforで列を取得(1行目と1列目は読み込まない)
for row in ws1.iter_rows(min_row = 2, min_col = 2):#iter_rows(min_row = 2, min_col = 2) :
for cell in row:
print('print(cell.value',cell.value)
#東京都
#2634
#2356
#・・・・・・・
#-------- ファイル書き出し -------------
wb.save('cvs2018b.xlsx')

コメント